基本优化思想与最小二乘法
基本优化思想与最小二乘法
在pytorch中最核心的基础数学工具就是梯度计算工具,也就是自动微分模块。
所谓优化思想,指的是利用数学工具求解复杂问题的基本思想,我们往往会先给出待解决问题的数值评估指标,并在此基础之上构建方程,采用数学工具,不断优化评估指标结果,以达到最优结果。
1 | import numpy as np |
一、简单线性回归的机器学习建模思路
- 回顾简单线性回归建模问题
1 | import matplotlib as mpl |
1 | A=torch.arange(1,5).reshape(2,2).float() |
tensor([[1., 2.],
[3., 4.]])
1 | plt.plot(A[:,0],A[:,1],'o') |
[<matplotlib.lines.Line2D at 0x1f7eff7f160>]

- 转化为优化问题
上述问题除了可以用矩阵方法求解以外,还可以将其转化为最优化问题,然后通过求解最优化问题的方法对其进行求解。最优化问题的转化分为两步。其一是确定优化数值指标,其二是确定优化目标函数。
如果我们希望通过一条直线拟合二维平面空间上分布的点,最核心的目标就是希望方程的预测值和真实值相差较小。假设真实的y值用y表示,预测值用表示,带入a、b参数,择优数值表示如下:
| 1 | 2 | a+b |
| 3 | 4 | 3a+b |
表示对应预测值
因此
上式就是两个点的预测值和真实值的差值平方和,也就是误差平方和——SSE(Sum of the Squard Errors)
此处我们只带入(1,2)和(3,4)两个点来计算SSE,也就是带入了两条数据来训练y=ax+b这个模型。
当a,b取何值时,SSE取值最小?SSE方程就是我们优化的目标方程(求最小值),因此上述方程也被成为目标函数,同时,SSE代表着真实值和预测值之间的差值(误差平方和),因此也被成为损失函数(预测值距真实值的损失)。
换而言之,当SSE取值最小时,a,b的取值就是最终线性回归方程的系数取值
目标函数和损失函数并不完全等价,但大多数目标函数都由损失函数构成
- 最优化问题的求解方法
在机器学习领域,大多数优化问题都是围绕目标函数(或者损失函数)进行求解。在上述问题中,我们需要围绕SSE求最小值,SSE是一个关于a和b的二元函数,要求最小值,需要最优化方法,选择优化方法并执行相应计算。
- 图形展示目标函数
使用Python中matplotlib包和Axes3D函数进行三维图像绘制
1 | from matplotlib import pyplot as plt |
1 | x=np.arange(-1,3,0.05) |
1 | fig=plt.figure() |
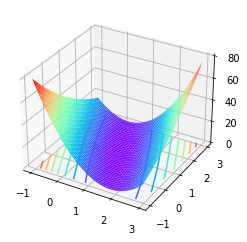
- 函数的凹凸性
绘制图像
1 | x=np.arange(-10,10,0.1) |
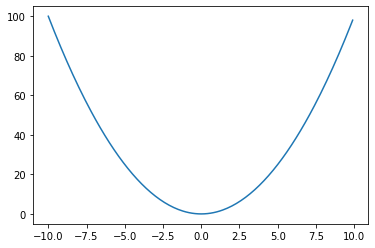
1 | x=np.arange(-5,5,0.5) |
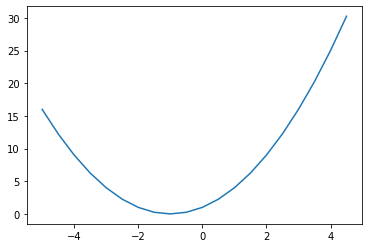
- SSE最小值
对于简单线性回归的损失函数,SSE是凸函数,因此对于SSE(a,b)=(2-a-b)2+(4-3a-b)2而言,最小值点就是a,b两个参数求偏导等于0的点。
所以a=1,b=1,因此y=x+1
利用偏导等于0得出的方程组求解线性回归方程参数,就是最小二乘法求解过程。
- 机器学习建模一般流程
- Step 1:提出基本模型
本节中,我们使用的直线(y=ax+b)去拟合二维平面空间中的点,这条直线就是基本模型,不同的模型能够使用不同的场景,在提出模型时,我们往往会预设一些影响模型结构或者实际判别性能的参数,如简单线性回归中a和b; - Step 2:确定损失函数和目标函数
围绕建模的目标,需要设置合理损失函数,并在此基础上设置目标函数,很多情况下,这二者是相同的,这里需要注意,损失函数不是模型,而是模型参数所组成的一个函数。 - Step 3:根据目标函数特性,选择优化方法,求解目标函数
目标函数既承载了我们优化的目标(让预测值和真实值尽可能接近),同时也是包含了模型参数的函数,因此,完成建模需要确定参数、优化结果需要预测值尽可能接近真实值这两方面需求就统一到了求解目标函数最小值的过程中了,也就是说,当我们围绕目标函数求解最小值时,也就完成了模型参数的求解。不同类型、不同性质的函数会影响优化方法的选择。在简单线性回归中,由于目标函数是凸函数,我们选取偏导数取值为0的点就是最小值点,进而使用最小二乘法完成a,b的计算,就是通过函数本身的性质进行最优化方法的选取。
二、第一个优化算法:最小二乘法
-
最小二乘法的代数表示方法
从更加严格的数学角度出发,最小二乘法有两种表示形式,分别是代数法表示和矩阵表示,我们先看最小二乘法的代数表示方法。首先,假设多元线性方程有如下形式
令则上式可写为
在机器学习领域,线性回归自变量系数一般命名为w,weight的简写,指自变量的权重
多元线性回归的最小二乘法的代数表示较为复杂,此处先考虑简单线性回归的最小二乘法表示形式,在简单线性回归中,w只包含一个分量,x也只包含一个分量,我们令此时的$ x_{i} $就是对应的自变量的取值。
优化目标可写为
通过偏导为0求得最终结果的最小二乘法求解过程为: